GEMM 优化: 双缓冲 (Prefetch) 和 Bank Conflict 解决
前言
本文主要是对 深入浅出GPU优化系列:GEMM优化(一) - 知乎, 深入浅出GPU优化系列:GEMM优化(二) - 知乎 以及 深入浅出GPU优化系列:GEMM优化(三) - 知乎 三篇文章相关内容的学习整理.
本文可以作为 如何优化 CUDA 矩阵乘内核以获得类似 cuBLAS 的性能: 工作日志 这篇文章的补充. 可以看作文中 Kernel 6 的后续优化. 在先前的这篇文章中, 作者原文中并没有针对 GEMM 的"双缓冲"和"Bank Conflict"进行具体讲解, 虽然译者根据原文作者提供的代码进行了这两部分的补充, 但译文中也提到了代码中存在的一些问题. 上述提到的三篇文章恰好提到了这部分内容, 通过比较, 笔者认为其提供了更好的解决方案, 值得学习.
双缓冲 (Prefetch)
双缓冲, 又被称作预取(Prefetch), 核心思想是通过两个缓冲区进行读写分离, 进而达到数据读写的 overlap, 掩盖指令延迟.
具体来讲, 在 GEMM 计算过程中, 基于线程块分片和线程分片, 每次线程块分片的迭代, 数据会先从全局内存(GMEM)加载到共享内存(SMEM), 每次线程分片的迭代, 数据会从共享内存加载到寄存器文件, 最后才是线程分片层次映射到 GPU 硬件计算单元进行的计算. 在这个过程中, 很直观的, 线程分片的计算依赖于 SMEM 加载到寄存器的数据, 而 SMEM 的数据又依赖于 GMEM 加载到 SMEM 的数据.
在没有考虑双缓冲的情况下, 由于 GMEM 的带宽有限, 这部分访存指令从发出到完成会有一段延迟(latency), 因此对 SMEM 的读取要等待 GMEM 读取并写入 SMEM 之后, 这就有一段延迟, 虽然 GPU 可以通过 SM 上切换其他线程块来掩盖这部分延迟, 但在 GMEM 中需要分配较多的 SMEM 和寄存器会导致 SM 中可以加载的线程块数量有限, 因此对 GMEM 的访存延迟便难以掩盖; 同样地, SMEM 虽然带宽相比于 GMEM 更高, 但指令执行效率仍不如计算单元上执行计算指令的效率, 因此, SMEM 加载数据到寄存器, 也有一段延迟, 计算单元需要等待, 而每次线程分片迭代时, 计算单元便会在对 SMEM 访存时停滞, 不能充分发挥其计算能力.
而双缓冲的思想顾名思义, 会对 GMEM 和寄存器开辟两倍的空间, 一部分用于读, 一部分用于写. 在每次迭代过程中, 分别对本次本次迭代的线程块分片/线程分片进行处理(加载到寄存器或进行计算), 并加载下一分片(到 SMEM 或寄存器); 从而在本次迭代过程中, 读写的数据没有依赖关系, 因此读写数据可以并行, 因此能够掩盖上面提到的访存延迟.
在代码上, 可以参考代码 sgemm_v1.cu.
template <
const int BLOCK_SIZE_M, // height of block of C that each thread block calculate (128)
const int BLOCK_SIZE_K, // width of block of A that each thread block load into shared memory (8)
const int BLOCK_SIZE_N, // width of block of C that each thread block calculate (128)
const int THREAD_SIZE_Y, // height of block of C that each thread calculate (8)
const int THREAD_SIZE_X, // width of block of C that each thread calculate (8)
const bool ENABLE_DOUBLE_BUFFER // whether enable double buffering or not
>
__global__ void Sgemm(
float * __restrict__ A,
float * __restrict__ B,
float * __restrict__ C,
const int M,
const int N,
const int K) {
// ..
// shared memory for A and B (Double Buffer)
__shared__ float As[2][BLOCK_SIZE_K][BLOCK_SIZE_M];
__shared__ float Bs[2][BLOCK_SIZE_K][BLOCK_SIZE_N];
// registers for C
float accum[THREAD_SIZE_Y][THREAD_SIZE_X] = {0};
// registers for A and B (Double Buffer)
float frag_a[2][THREAD_SIZE_Y];
float frag_b[2][THREAD_SIZE_X];
// registers load global memory
const int ldg_num_a = BLOCK_SIZE_M * BLOCK_SIZE_K / (THREAD_NUM_PER_BLOCK * 4); // 128*8/(256*4)=1
const int ldg_num_b = BLOCK_SIZE_K * BLOCK_SIZE_N / (THREAD_NUM_PER_BLOCK * 4); // 8*128/(256*4)=1
float ldg_a_reg[4*ldg_num_a];
float ldg_b_reg[4*ldg_num_b];
// ...
// transfer first BLOCK tile and THREAD from global mem to shared mem
// load A from global memory to shared memory
// ...
// load B from global memory to shared memory
// ...
__syncthreads();
// load A from shared memory to register
// ..
// load B from shared memory to register
// ...
int write_stage_idx = 1;
int tile_idx = 0;
do{
tile_idx += BLOCK_SIZE_K;
// load next BLOCK tile from global mem (GMEM to temp register)
if(tile_idx< K){
#pragma unroll
// load A from global memory to temp register
// ...
// load B from global memory to temp register
// ...
}
int load_stage_idx = write_stage_idx ^ 1;
#pragma unroll
for(int j=0; j<BLOCK_SIZE_K-1; ++j){
// load next THREAD tile from shared mem to register
// load A from shared memory to register
// ...
// load B from shared memory to register
// ...
// compute C THREAD_SIZE_X x THREAD_SIZE_Y of current THREAD tile
// ...
}
if(tile_idx < K){
// load next BLOCK tile from global mem (temp register to SMEM)
// load A from temp register(global memory) to shared memory
// ...
// load B from temp register(global memory) to shared memory
// ...
// use double buffer, only need one sync
__syncthreads();
// switch
write_stage_idx ^= 1;
}
// load first THREAD tile of current BLOCK tile from shared mem to register of next iter
// load A from shared memory to register
// ...
// load B from shared memory to register
// ...
//compute last THREAD tile mma THREAD_SIZE_X x THREAD_SIZE_Y
// ...
}while(tile_idx< K);
// store back to C
// ...
}
以上为 GEMM kernel 的执行逻辑, 这里笔者仅保留了关键部分和注释.
直观看来, 代码整体上仍然是顺序执行的逻辑, 感觉好像并不能达到 overlap 的目的, 因为还是读一个分片写一个分片的代码逻辑.
实则不然. 核心在于要理解代码对应的指令发射与执行完成的过程. 在 GPU 上, 访存和计算对应着不同的硬件单元, 这两个计算单元是可以并行执行的, 代码的顺序执行对应的是编译后硬件指令发射的顺序过程, 指令的发射过程虽然是顺序的, 但发射速度很快, 而指令发出后需要一段时间才能执行完成, 这也就对应着某个指令需要相应的时钟周期才能完成, 访存的延迟也就是访存指令相比于计算指令有更长的时钟周期.
上述双缓冲实现与未使用双缓冲的 kernel 6 相比, 很重要的一点不同就是 __syncthreads() 的数量. 在 kernel 6 中, 需要两个 __syncthreads(), 一个是在从 GMEM 加载当前线程块分片到 SMEM 后, 一个是在计算完当前线程块分片结果时. 因此对应的, 在加载线程块分片到 SMEM 完成之前, 就无法进行线程分片的迭代和计算; 同样的, 在当前线程块分片计算完毕前, 也不能加载下一线程块分片到 SMEM. 而双缓冲实现中, 由于加载和计算的是两个分片, 互不依赖, 因此仅有一个__syncthreads(). 这样, 在线程块层面, 由于少了一次同步, GPU 可以提前发射后面线程分片迭代计算的指令, 从而掩盖从 GMEM 加载到 SMEM 的访存延迟.
在线程层面, 在没有双缓冲的 kernel 6 中, 每次线程分片迭代时, 由于计算的指令依赖于前面 SMEM 的访存的指令, 因此需要等待数据加载到寄存器完毕后才能发射后面矩阵乘的计算指令. 而双缓冲的实现中, 同样由于加载和计算的是两个线程分片, 因此指令上并没有依赖关系, 计算指令可以无需等待数据加载完成就可以进行发射, 从而掩盖从 SMEM 加载到寄存器的访存延迟.
总的来讲, 这里双缓冲利用的是指令级并行, 双缓冲使得读写分离, 在指令层面读写指令不再依赖, 从而 GPU 可以无需等待的发射更多指令, 从而掩盖访存指令的延迟, 也即达到了读写的 overlap. (笔者参考了 深入浅出GPU优化系列:GEMM优化(二) - 知乎 中用户"one hundred"和"柱子柱子"的评论.)
在上面代码中, 可以看到一个比较有特点地方, 即在线程块分片从 GMEM 加载到 SMEM 时, 会存到临时寄存器 ldg_a_reg 和 ldg_b_reg 中. 首先, 在算力 8.0 的 GPU 之前, 数据从 GMEM 到 SMEM 时是需要隐式的通过寄存器中转的, 因此这样相当于用代码显式表达了出来, 并不会引入额外开销. 但这里有一点很重要, 就是从 GMEM 加载线程块分片到寄存器后, 并没有在 for 循环中(上述注释没有表现, 具体见完整代码)接着写入 SMEM, 而是中间夹着对线程块分片迭代的 for 循环之后, 再从临时寄存器写入 SMEM. 结合上面的指令级并行的描述, 其实也就容易理解了. 如果紧接着就写入 SMEM, 那么前后代码(指令)由于操作一个分片的数据而有了依赖, 因此写入 SMEM 的指令就需要等待前面对 GMEM 的读取指令, 从而降低了掩盖指令延迟的效果.
不过有意思的是, 这里笔者尝试把中间的"对线程块分片迭代的 for 循环"放到 do-while 循环的最前面, 后面跟着两个 GMEM 到临时寄存器的循环, 最后是两个临时寄存器到 SMEM 的循环, 发现对于一些较大的矩阵(M N K >= 2048)有时能达到比原代码略高一些的性能.
而对于算力 8.0 的 GPU, 实际上可以参考 如何优化 CUDA 矩阵乘内核以获得类似 cuBLAS 的性能: 工作日志#Kernel 12, 借助 cuda::memcpy_async() 可以完成数据从 GMEM 到 SMEM 而无需寄存器的直接搬运.
Bank Conflict 的解决
对于上述的双缓冲的实现, 更多是从代码的执行顺序上进行调整, 对于代码的核心逻辑, 实际上与 kernel 6 是一致的.
因此, 对于 SMEM 的访存, 此处也有着与 kernel 6 一样的 bank conflict 问题. 具体的分析, 笔者在 如何优化 CUDA 矩阵乘内核以获得类似 cuBLAS 的性能: 工作日志#Kernel 7 中有具体讨论. 与 kernel 7 相同, 此处主要解决的是对 SMEM 读取(SMEM 到寄存器)的 bank conflict, 对于 SMEM 写入(GMEM 到 SMEM, As 有 bank conflict)没有考虑.
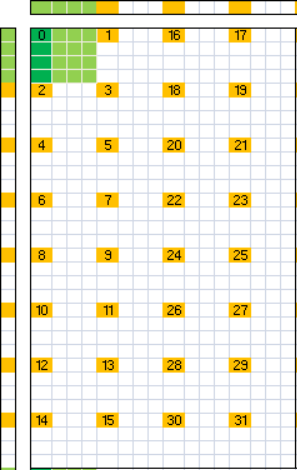
对于当前的 bank conflict, 如下图所示. 图中左侧和右侧分别是当前线程分片对应的 SMEM As 和 Bs 的一行数据, 上面的索引对于的是 SMEM 的 32 个 bank. warp 中的 32 个线程分别由橙色方块标识, 每个线程计算的 8×8 大小的数据, 由黑色实线框出, 每个线程在从 SMEM 加载时可以分成对 As 和 Bs 各 2 个 float 4 大小的加载. 其中, warp 0 线程 0 的加载和计算情况用绿色进行了标识.
可以看到, 对于每个 warp, 其线程是按照 2×16 的大小排布的, 每个线程分别读取 8 个 As 和 Bs 的数据. 因此, 对于 As, 一个 warp 只会访问其 16 个元素, 对应 16 个 bank, 因此没有 bank conflict; 而对于 Bs, 可以在图中直观的看到, threadIdx 相差 4 的线程, 访问相同的 8 个 bank, 因此会有 bank conflict.
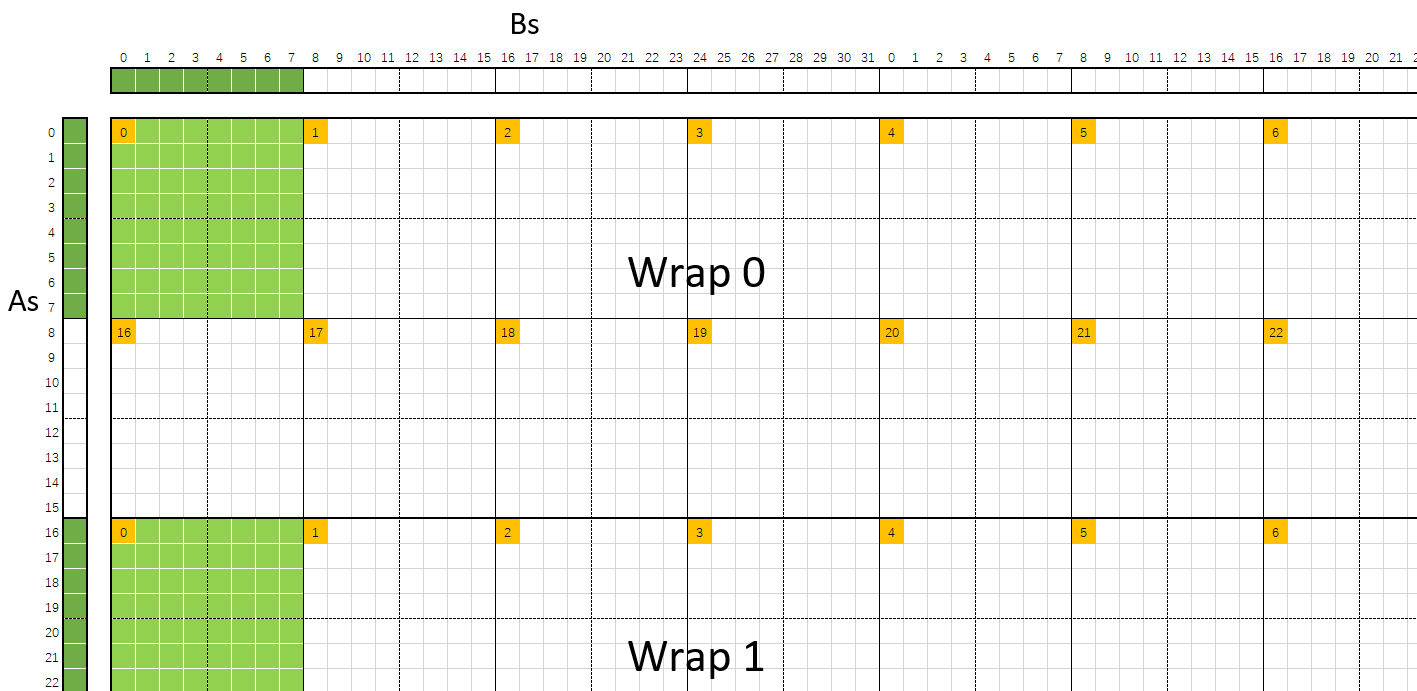
对于 bank conflict 的解决, 深入浅出GPU优化系列:GEMM优化(三) - 知乎 使用了 NervanaSystems/maxas - GitHub 中使用的一种方法.
对于原本 SMEM 读取代码:
#pragma unroll
for (int thread_y = 0; thread_y < THREAD_SIZE_Y; thread_y += 4) {
FETCH_FLOAT4(frag_a[(j+1)%2][thread_y]) = FETCH_FLOAT4(As[load_stage_idx][j+1][THREAD_SIZE_Y * ty + thread_y]);
}
// load B from shared memory to register
#pragma unroll
for (int thread_x = 0; thread_x < THREAD_SIZE_X; thread_x += 4) {
FETCH_FLOAT4(frag_b[(j+1)%2][thread_x]) = FETCH_FLOAT4(Bs[load_stage_idx][j+1][THREAD_SIZE_X * tx + thread_x]);
}
改成了
//load index of the tile
const int warp_id = tid / 32;
const int lane_id = tid % 32;
const int tile_index_a = (warp_id / 4) * 32 + ((lane_id % 16) / 2) * 4;
const int tile_index_b = (warp_id % 4) * 16 + (lane_id / 16) * 8 + (lane_id % 2) * 4;
FETCH_FLOAT4(frag_a[0][0]) = FETCH_FLOAT4(As[0][0][a_tile_index]);
FETCH_FLOAT4(frag_a[0][4]) = FETCH_FLOAT4(As[0][0][a_tile_index + 64]);
// load B from shared memory to register
FETCH_FLOAT4(frag_b[0][0]) = FETCH_FLOAT4(Bs[0][0][b_tile_index]);
FETCH_FLOAT4(frag_b[0][4]) = FETCH_FLOAT4(Bs[0][0][b_tile_index + 64]);
在 maxas 中, tile_index_a 和 tile_index_b 分别对应 readAs 和 readBs:
// readAs = ((tid128 >> 4) | ((tid >> 1) & 7)) << 4;
// readBs = (((tid & 0x70) >> 3) | (tid & 1)) << 4 + 4096;
$insert{"j${j}c0"} = sprintf "--:-:-:-:1 %s LDS.U.128 j%dAx00, [readAs + 4x<%d*128 + 00>];\n", $rsPred, $nOdd, $rsOffset;
$insert{"j${j}c2"} = sprintf "--:-:-:-:1 %s LDS.U.128 j%dBy00, [readBs + 4x<%d*128 + 00>];\n", $rsPred, $nOdd, $rsOffset;
$insert{"j${j}c4"} = sprintf "--:-:-:-:1 %s LDS.U.128 j%dAx64, [readAs + 4x<%d*128 + 64>];\n", $rsPred, $nOdd, $rsOffset;
$insert{"j${j}c6"} = sprintf "--:-:1:-:1 %s LDS.U.128 j%dBy64, [readBs + 4x<%d*128 + 64>]; // Set Dep 1\n", $rsPred, $nOdd, $rsOffset;
首先, 这两种计算得到的 warp 排布是相同的. 其次, maxas 是一个 SASS 层面的工作, 其 readAs 和 readBs 的单位是字节, 因此对于线程块中的同一个线程, 其 readAs 和 readBs 大小是 tile_index_a 和 tile_index_b 的四倍, 后者的单位是一个 float 元素.
直接看这个算式有些晦涩, 这里直接给出 maxas 的图片.
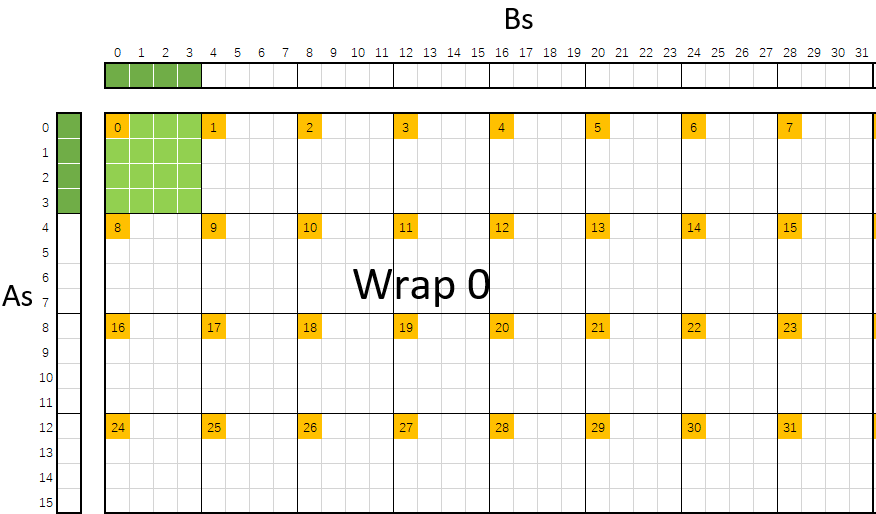
首先是 warp 的排布, 对于 block_size 大小为 256, 每个线程块有 8 个 warp. 如图, 按照 2×4 方式进行排布, 图中绿色部分仍然是 warp 0 的 线程 0 需要计算的 8×8 个数据, 可以看到, 此时并不像之前 kernel 6 那样是在一起的, 而是按照 warp 的大小分成了 4 部分.

而在 warp 内线程的排布, 如下图所示, 线程按照 8×4 的排布. 这里比较独特的是采用了一种 “zigzag” 的排布方式, 在 maxas 的文档中, 原文如此描述, “The straight forward approach is to load in a simple scanning pattern either down or across. This turns out to produce the mysterious bank conflicts. But if we use a zigzag pattern illustrated by the thread numbers it works.” 即这样做主要是避免一种"神秘的 bank conflict".
回到 bank conflict, 可以看到, 此时每个 warp 在一次处理中, 会访问 8×4=32 个 As 数据 4×4=16 个 Bs 数据, 因此都没有 bank conflict.
笔者认为, 这里的核心实际上就是 warp 分片, 将原本 kernel 6 在一个 warp 对应 1 个 16×128 的 warp 分片, 变为了此处的 4 个 32×16 的 warp 分片, 从而避免了 bank conflict.
在不考虑"神秘的 bank conflict"的情况下, 实际上只要把线程块分片按照 warp 进行分片, 实际上就能解决此处 SMEM 读取时的 bank conflict, 而 warp 内的线程排布也可以不使用这里的 zigzag 的做法. 比如在 sgemm_v3.cu 中, 代码作者实际上使用的是 4×2 的 warp 布局, warp 中的每个线程按照 4×8 进行排布, 每个 warp 对应 16×32 的数据. 如下图所示, 可以看到, 仍然没有 bank conflict.
const int warp_id = tid / 32;
const int lane_id = tid % 32;
const int a_tile_index = warp_id / 2 * 16 + lane_id / 8 * 4
const int b_tile_index = warp_id % 2 * 32 + lane_id % 8 * 4;
关于 warp 分片, 这里也可以参考 如何优化 CUDA 矩阵乘内核以获得类似 cuBLAS 的性能: 工作日志#Kernel 10, 其讲的也是 warp 分片. 但是与此处还是有一些不同. 此处可以理解为先对矩阵 C 的线程块分片(128×128)划分为了 2×2=4 个分块, 每个分块按照 warp 数量(此处是 256 线程, 8 个 warp)进行 4×2 的排布, 其中每个 warp 对应 16×32 的数据, 一整个分块对应 64×64 的数据. 而在 kernel 10 中, 对于矩阵 C 的线程块分片, 直接按照 warp 数量(文中是 128 线程, 4 个 warp)进行 2×2 排布的划分, 每个 warp 对应 32×64 的数据, 需要 warp 层面迭代 2×2=4 次, 每次处理 16×32 的数据(文中每个线程处理 4×4 的数据). 简而言之, 此处的 warp 分片, 使得线程块内所有 warp 同一次迭代的数据是连续一块, 不同迭代的数据是分散的多块; 而 kernel 10 中则是每个 warp 多次迭代的数据是连续的一块, 不同 warp 同一次迭代的数据则是分散的多块. 至于这两种方式哪一种更好, 笔者目前并不清楚, 不过个人更偏向此处的做法, 因为所有 warp 同一次迭代的数据是连续的, 可能会更利用与缓存, 当然这也只是个人主观猜测, 应该还是以具体实验为准.
还值得一提的是, 在 如何优化 CUDA 矩阵乘内核以获得类似 cuBLAS 的性能: 工作日志#Kernel 7 也提出了一种解决 bank conflict 的方式, 主要是通过对 Bs 进行 ROW=8, COL=16 的 swizzle 操作实现的. 相比与此处, kernel 7 的实现还是有一定局限的, 因为其导致在访问 Bs 时不能进行 float4 的合并读取, 而是只能按照 float 元素 for 循环读取 8 个元素到寄存器, 访存效率相对低一些.
最后, 由于相比于之前每个线程计算 8×8 的矩阵 C 的结果, 此时变成了 4 个 4×4 的结果. 因此在从寄存器写回结果到 GMEM 时, 代码也需要随之进行调整, 变成分别对 4 个分块进行写回.
// store C00 block
for (int i = 0; i < 4; i++) {
FETCH_FLOAT4(C[OFFSET(BLOCK_SIZE_M * by + c_block_row + i,
BLOCK_SIZE_N * bx + c_block_col, N)]) =
FETCH_FLOAT4(accum[i][0]);
}
// store C01 block
for (int i = 0; i < 4; i++) {
FETCH_FLOAT4(C[OFFSET(BLOCK_SIZE_M * by + c_block_row + i,
BLOCK_SIZE_N * bx + c_block_col + 64, N)]) =
FETCH_FLOAT4(accum[i][4]);
}
// store C10 block
for (int i = 0; i < 4; i++) {
FETCH_FLOAT4(C[OFFSET(BLOCK_SIZE_M * by + c_block_row + 64 + i,
BLOCK_SIZE_N * bx + c_block_col, N)]) =
FETCH_FLOAT4(accum[i + 4][0]);
}
// store C11 block
for (int i = 0; i < 4; i++) {
FETCH_FLOAT4(C[OFFSET(BLOCK_SIZE_M * by + c_block_row + 64 + i,
BLOCK_SIZE_N * bx + c_block_col + 64, N)]) =
FETCH_FLOAT4(accum[i + 4][4]);
}
最后的最后, 深入浅出GPU优化系列:GEMM优化(三) - 知乎 文章中对应 C 代码的优化还提到了 2 个技巧(技巧 1 和技巧 3), 不过文章作者并没有具体讲, 在代码 sgemm_v3.cu 中也没有体现, 笔者在此就予以省略. 包括文中后面利用 SASS 对寄存器 bank conflict 的优化, 基本上是参照 maxas 的实现, 不过笔者对其不太了解, 也没有读明白, 由于时间关系也予以省略.
参考资料
- 深入浅出GPU优化系列:GEMM优化(一) - 知乎
- 深入浅出GPU优化系列:GEMM优化(二) - 知乎
- 深入浅出GPU优化系列:GEMM优化(三) - 知乎
- How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog - SIBOEHM
- 如何优化 CUDA 矩阵乘内核以获得类似 cuBLAS 的性能: 工作日志
- GitHub - NervanaSystems/maxas